Gitbash_乱码记
更换电脑,重装hexo时,gitbash输出乱码.
系统字符集编码与Gitbash字符集编码不一致,解决方法打开win10语言设置,依次点击下图选项,更改为UTF-8编码,重启电脑即可解决.[吐了,其他软件又乱码了]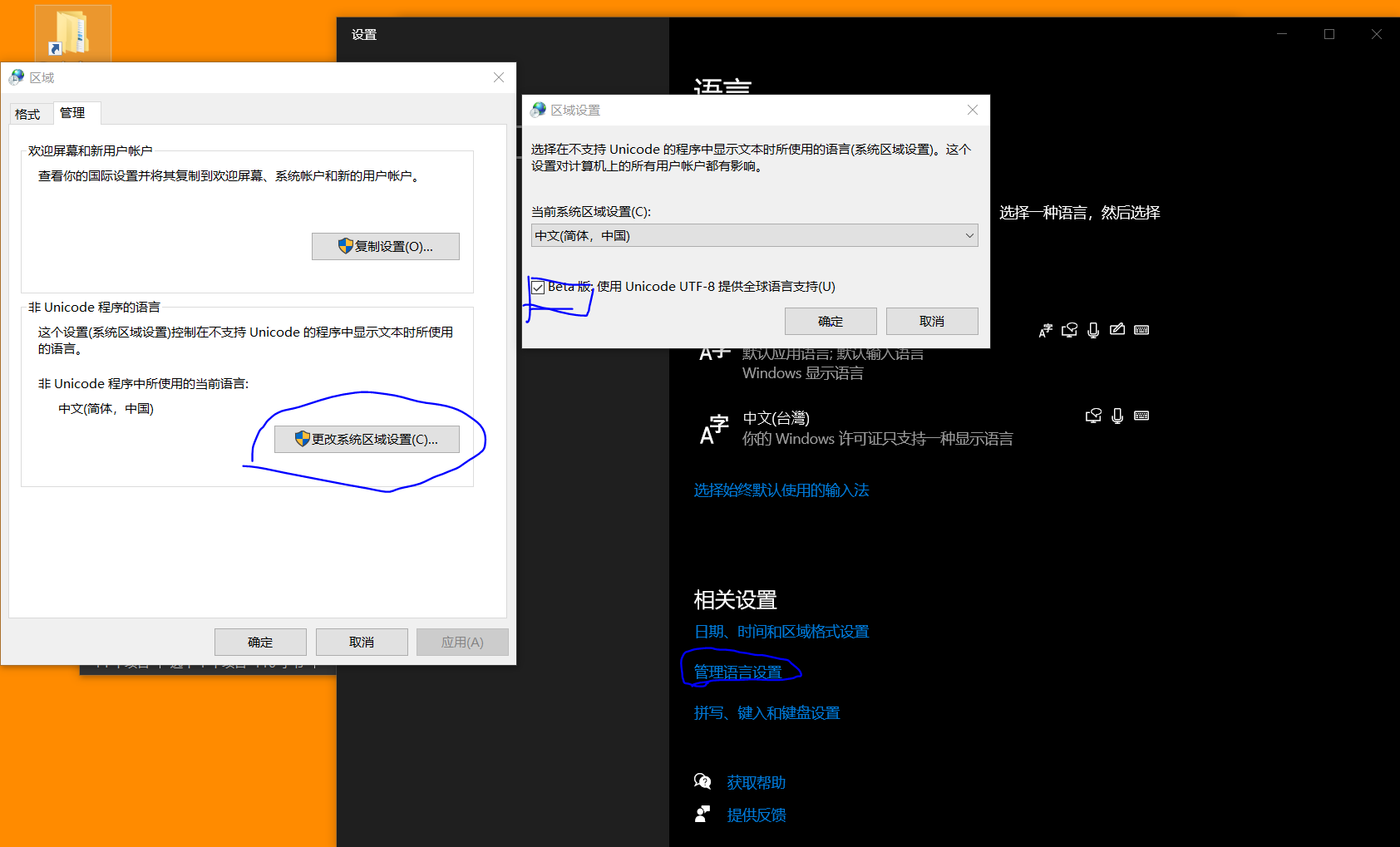
更换电脑,重装hexo时,gitbash输出乱码.
系统字符集编码与Gitbash字符集编码不一致,解决方法打开win10语言设置,依次点击下图选项,更改为UTF-8编码,重启电脑即可解决.[吐了,其他软件又乱码了]
conda list 查看安装了哪些包。
conda env list 或 conda info -e 查看当前存在哪些虚拟环境
conda update conda 检查更新当前conda
创建Python虚拟环境。