[toc]
Step1: 配置远程登录
由于我们没有安装桌面环境,虚拟机中Centos的终端相对简陋,我们在宿主机终端通过SSH登录Centos即可.(主机系统为Ubuntu ,我们不需要下载其他的远程连接工具)
将服务器IP设为静态
打开网络配置文件,命令如下
sudo vi /etc/sysconfig/network-scripts/ifcfg-ens33用如下内容替换文件中的内容,将注释内容更改为自己服务器相应的。
TYPE="Ethernet" BOOTPROTO="static" DEVICE="ens33" ONBOOT="yes" IPADDR=192.168.200.101 #IP NETMASK=255.255.255.0 #子网掩码 GATEWAY=192.168.200.2 #网关 DNS1=114.114.114.114重启网络
sudo service network restart
在宿主机hosts文件中添加相应服务器的域名映射.
sudo gedit /etc/hosts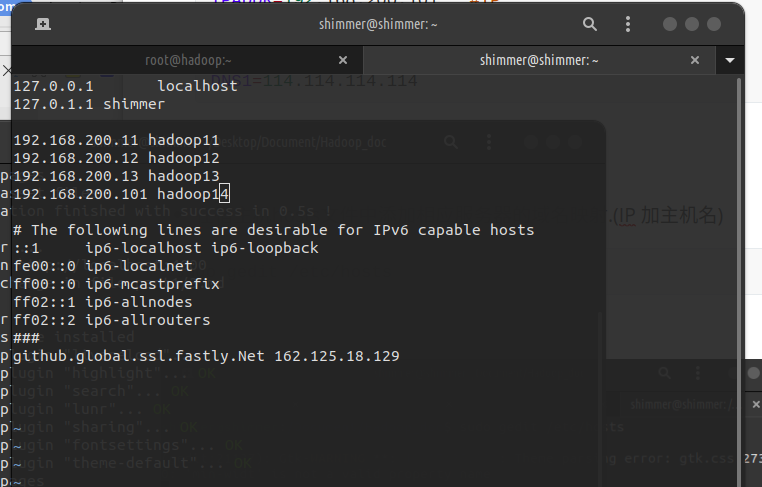
测试SSH登录
sudo ssh hadoop14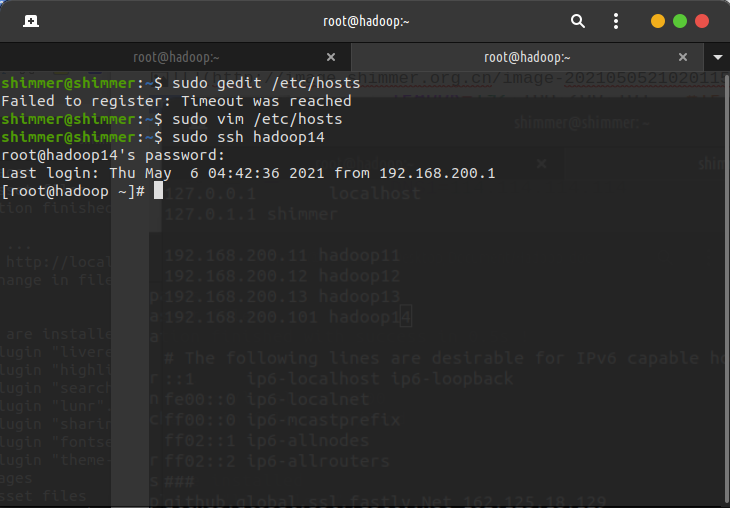
更改主机名
sudo vi /etc/hostname # 修改为master
Step2: 安装JDK
Hadoop支持Openjdk ,因此我们可用使用命令 安装openjdk7,替代Oracle JDK。
su -c "yum install java-1.7.0-openjdk"查看Java版本
java -version
配置Java环境变量
sudo vi /etc/profile # java export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.261-2.6.22.2.el7_8.x86_64
Step3: 安装Hadoop2.7.3
新建资源目录
sudo mkdir /opt/softwares sudo mkdir /opt/modules
安装wget
yum install wget下载hadoop2.7.3 ,速度较慢
推荐使用百度网盘下载到本地后,使用scp命令上传到服务器
链接: https://pan.baidu.com/s/1W_S5BcghFqjwdUi0GfqeSQ 密码: p2ek
wget https://archive.apache.org/dist/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz #在线下载 sudo scp -r hadoop-2.7.3.tar.gz hadoop14:/opt/softwares/ #本地上传解压hadoop,转到hadoop文件夹下,执行以下命令。
tar -xvf hadoop-2.7.3.tar.gz
关闭防火墙 由于hadoop需要打开的端口太多,因此此处暂时关闭了防火墙。要关闭防火墙,必须在root用户下使用以下命令:
#Close the firewall systemctl stop firewalld.service #Turn off boot and self-start systemctl disable firewalld.service创建数据存储目录
cd /usr/local/hadoop mkdir tmp mkdir -p hdfs/data hdfs/name配置环境变量
sudo vi /etc/profile export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.261-2.6.22.2.el7_8.x86_64 export PATH=$PATH:$JAVA_HOME/bin export CLASSPATH=.:$JAVA_HOME/jre/lib:$JAVA_HOME/lib:$JAVA_HOME/lib/tools.jar export HADOOP_HOME=/opt/softwares/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin 使用以下命令初始化变量。 source /etc/profile 完成后,您现在可以检查是否设置了环境变量。运行以下命令。 echo $JAVA_HOME 它应该提供以下输出。 /usr/lib/jvm/java-1.7.0-openjdk-1.7.0.261-2.6.22.2.el7_8.x86_64 同时运行以下命令。 echo $HADOOP_HOME 它应该显示以下输出。 /opt/softwares/hadoop
配置,进入hadoop目录下
1 修改core-site.xml文件
<configuration> <property> <name>fs.default.name</name> <value>hdfs://master:9000</value> # </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/home/hadoop/tmp</value> # <description>Abase for other temporary directories.</description> </property> </configuration>2 修改hdfs-site.xml文件
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>linux-node1:9001</value> <description># View HDFS status </description> through the web interface </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/hadoop/dfs/name</value> # </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/hadoop/dfs/data</value> # </property> <property> <name>dfs.replication</name> <value>2</value> <description># Each Block has two backups </description> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration>3 修改mapred-site.xml (重命名mapred-site.xml.template并添加以下内容) (这是MapReduce任务的配置。因为Hadoop 2.x使用yarn框架来实现分布式部署,所以必须在mapreduce.framework.name属性下配置yarn。mapred.map.tasks和mapred.reduce.tasks分别是map和reduce的任务数。)
mv mapred-site.xml.template mapred-site.xml<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> # </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> # </property> </configuration>4 配置节点yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>master:8032</value> # </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> # </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8031</value> # </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>master:8033</value> # </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>master:8088</value> # </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>8192</value> </property> </configuration>5 配置hadoop环境变量
[root@master ~]$ vi /etc/profile #Replace the previously modified java environment variable. export JAVA_HOME=java-1.7.0-openjdk-1.7.0.261-2.6.22.2.el7_8.x86_64 export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export HADOOP_HOME=/usr/local/hadoop export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin[hadoop@master ~]$ vi ~/.bashrc export JAVA_HOME=java-1.7.0-openjdk-1.7.0.261-2.6.22.2.el7_8.x86_64 export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export HADOOP_HOME=/usr/local/hadoop export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
Step4:克隆虚拟机
克隆Hadoop02,Hadoop03节点。
关闭虚拟机master,然后在VMware左侧的虚拟机列表中右键单击【Hadoop01】,选择【Manager】->【Clone】
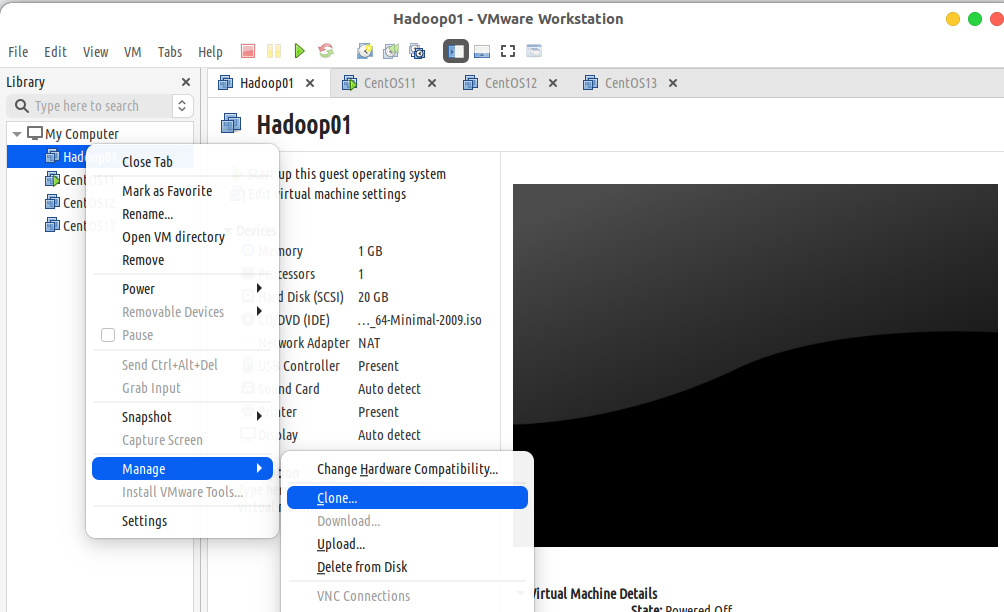
点击下一步,在Clone Type处选择Create a full clone
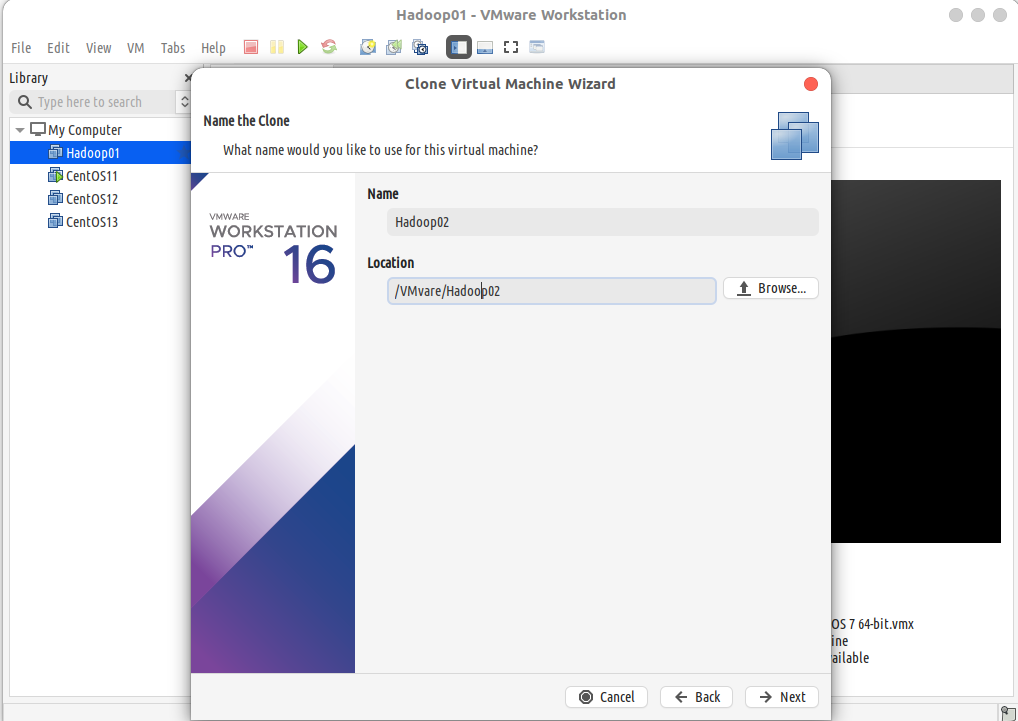
修改虚拟机名称与文件路径,点击完成,等待克隆完成
克隆Hadoop03的步骤同上
修改节点主机名
首先修改Hadoop02和Hadoop03的主机名(他们目前都是master)
vi /etc/hostnames # Hadoop02修改为slave1 # Hadoop03修改为slave2
修改IP
sudo vi /etc/sysconfig/network-scripts/ifcfg-ens33 # 修改Hadoop02的IP为192.168.200.102 # 修改Hadoop03的IP为192.168.200.103 sudo service network restart #重启网络
添加域名解析
分别修改Hadoop01,Hadoop02,Hadoop03,及宿主机的域名映射文件 sudo vi /etc/hosts # 在host文件末尾追加以下内容: # 192.168.200.101 master # 192.168.200.102 slave1 # 192.168.200.103 slave2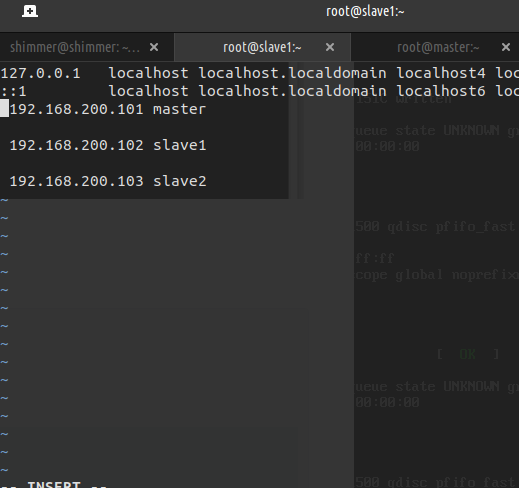
在各节点使用ping命令检查是否配置成功:
ping master ping slave1 ping slave2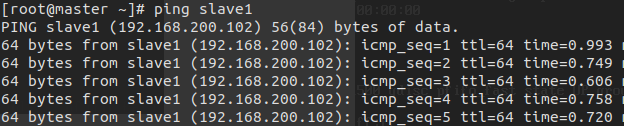
Step5:配置ssh免密登录
生成密钥文件:
ssh-keygen -t rsa # 生成中按enter即可 # 在三台服务器中执行此命令SSH分发
ssh-copy-id master ssh-copy-id slave1 ssh-copy-id slave2 # 在三台服务器中执行上述命令 #Are you sure you want to continue connecting (yes/no)? 需输入yes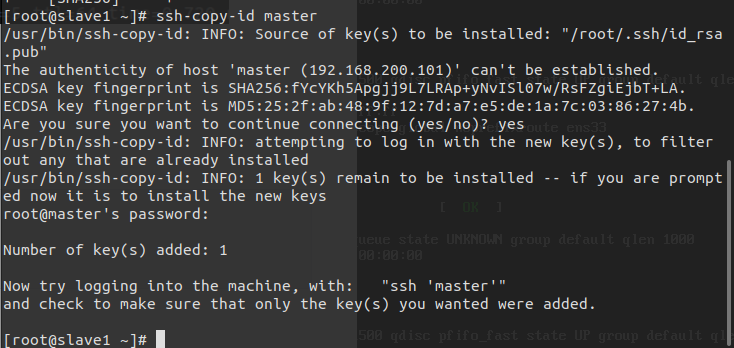
验证SSH登录
ssh master ssh slave1 ssh slave2 #三台机器中分别执行上述命令
格式化一个新的分布式文件系统:
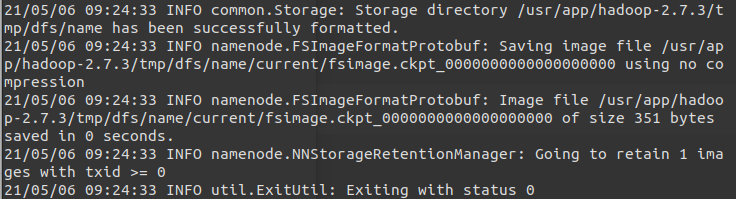
hadoop namenode -format
#在第一使用 Hadoop 之前,需要先格式化
#在master上,执行上述命令
#显示 tmp/dfs/name has been successfully formatted
#及Exiting with status 0 表明格式化成功
Step6: 启动Hadoop
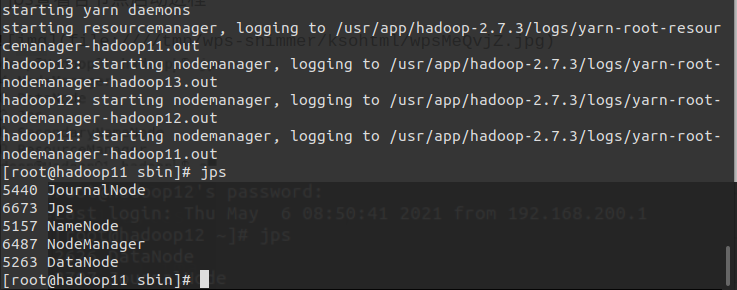
#在master上执行
cd /usr/app/hadoop-2.7.3/sbin/
./start-all.sh
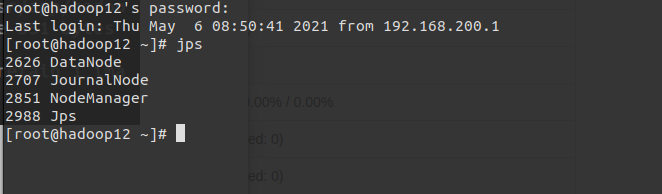
jps查看各节点启动进程
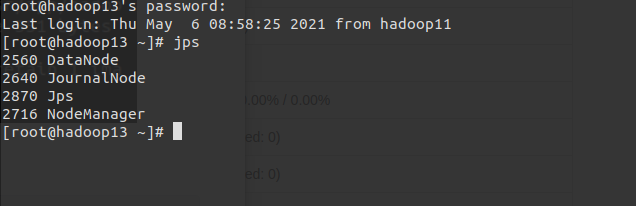
Step7: 集群web
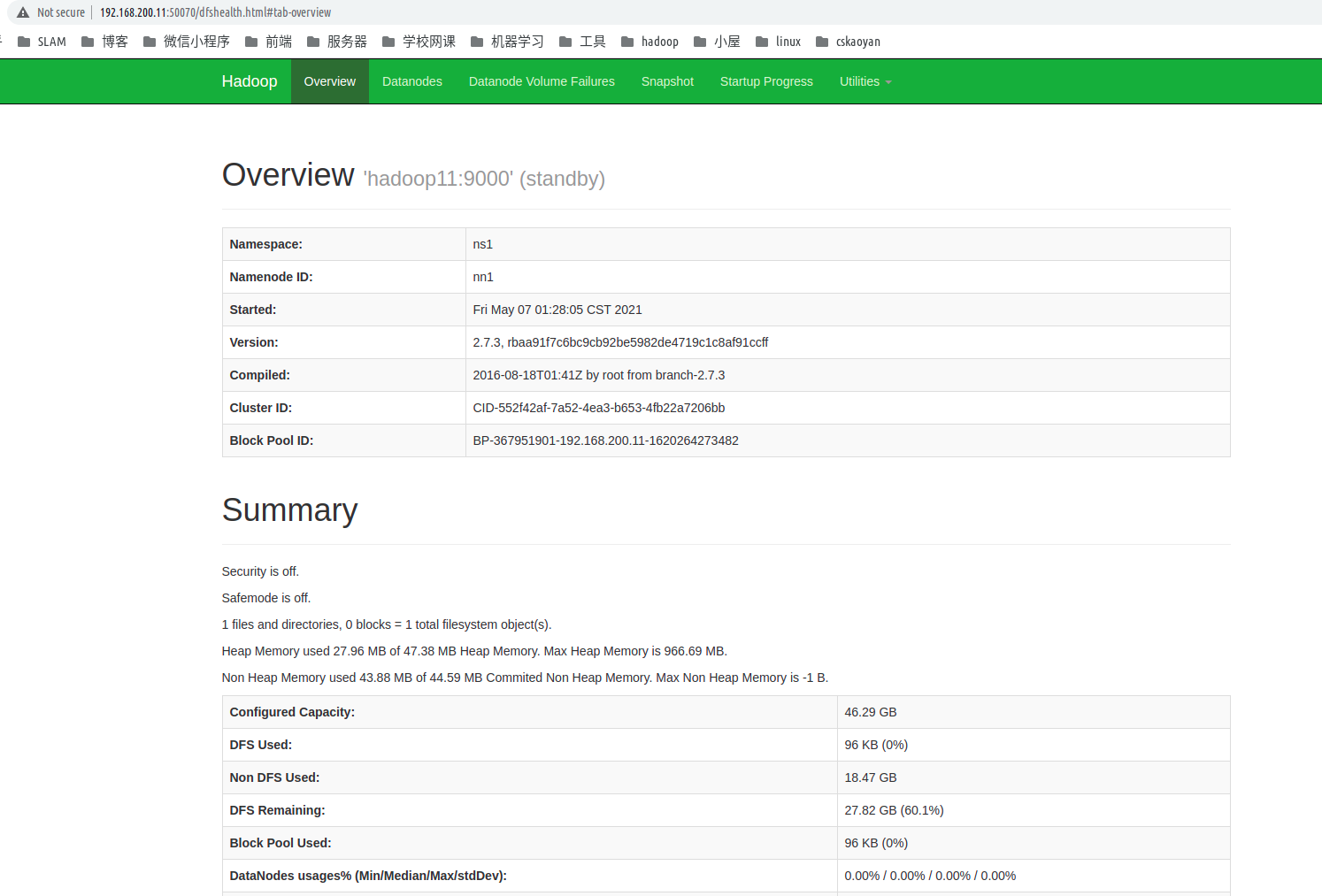
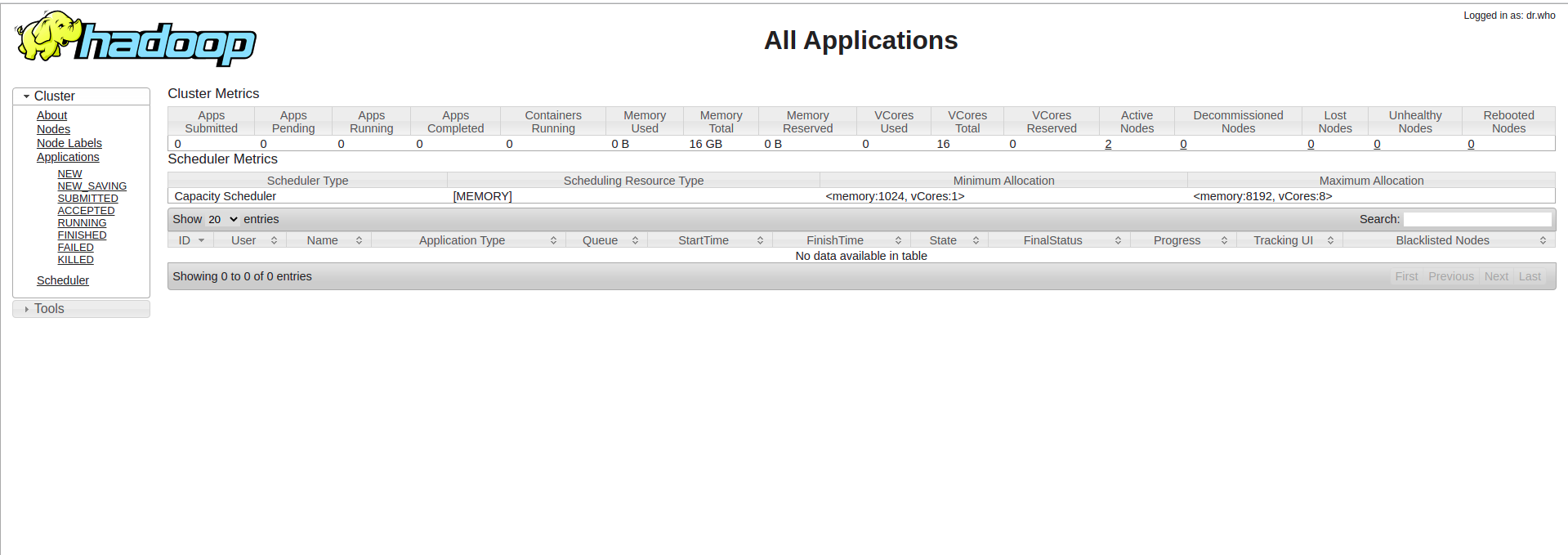
Hadoop集群启动并运行后,可以通过web-ui进行集群查看,如下所述:
然后本机访问http://(Hadoop01 IP):50070 #hdfs
http://(Hadoop01 IP):8088 #yarn
Step8:验证
验证 HDFS HA 首先向 hdfs 上传一个文件
hadoop fs -put /etc/profile / hadoop fs -ls /
通过浏览器访问:http://192.168.200.11:50070
验证 YARN
运行一下 hadoop 提供的 demo 中的 WordCount 程序:
hadoop jar /usr/app/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /profile /out
至此,hadoop安装完成 下节Zookeeper安装